
使用 kubeadm 创建高可用 k8s 集群
00、准备开始
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
- 每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
- 2 CPU 核或更多
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息
- 开启机器上的某些端口。请参见这里 了解更多详细信息
- 禁用交换分区。为了保证 kubelet 正常工作,必须 禁用交换分区
01、集群规划
集群节点规划如下
| 主机名 | 主机 IP | 主机配置 | 主机角色 | 系统 |
|---|---|---|---|---|
| k8s-master01 | 192.168.30.37 | 2C4G | Control plane | CentOS Linux release 7.6.1810 (Core) |
| k8s-master02 | 192.168.30.38 | 2C4G | Control plane | CentOS Linux release 7.6.1810 (Core) |
| k8s-master03 | 192.168.30.39 | 2C4G | Control plane | CentOS Linux release 7.6.1810 (Core) |
| k8s-node01 | 192.168.30.41 | 2C4G | Worker node | CentOS Linux release 7.6.1810 (Core) |
| k8s-node02 | 192.168.30.42 | 2C4G | Worker node | CentOS Linux release 7.6.1810 (Core) |
10、系统初始化设置
修改主机名称添加主机映射
修改主机名称
$ hostnamectl set-hostname $NODE-NAME
NODE-NAME:表示将要命名给各节点的主机名
添加主机映射
$ cat <<EOF | sudo tee -a /etc/hosts
192.168.30.37 k8s-master01
192.168.30.38 k8s-master02
192.168.30.39 k8s-master03
192.168.30.41 k8s-node01
192.168.30.42 k8s-node02
EOF
确保 MAC 地址和 product_uuid 的唯一性
- 使用命令
ip link或ifconfig -a来获取网络接口的 MAC 地址 - 使用
sudo cat /sys/class/dmi/id/product_uuid命令对 product_uuid 校验
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装 失败。
防火墙设置
内网环境可以直接关闭防火墙。如需开启防火墙,启用某些必要的端口后才能使 Kubernetes 的各组件相互通信。
方式一:禁用防火墙
所有节点关闭系统防火墙
$ systemctl disable firewalld --now
方式二:启用所需端口
注意:使用的 Pod 网络插件也可能需要开启某些特定端口。由于各个 Pod 网络插件的功能都有所不同, 请参阅他们各自文档中对端口的要求。
检查所需端口
控制面
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API server | 所有 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 10259 | kube-scheduler | 自身 |
| TCP | 入站 | 10257 | kube-controller-manager | 自身 |
尽管 etcd 的端口也列举在控制面的部分,但也可以在外部自己托管 etcd 集群或者自定义端口。
工作节点
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 30000-32767 | NodePort Services† | 所有 |
† NodePort Services 的默认端口范围。
所有默认端口都可以重新配置。当使用自定义的端口时,需要打开这些端口来代替这里提到的默认端口。
一个常见的例子是 API 服务器的端口有时会配置为443。或者你也可以使用默认端口,把 API 服务器放到一个监听443 端口的负载均衡器后面,并且路由所有请求到 API 服务器的默认端口。
启用所需端口
在所有节点上启用各自所需的端口
# 控制平面节点
$ firewall-cmd --permanent --add-port=6443/tcp
$ firewall-cmd --permanent --add-port=2379-2380/tcp
$ firewall-cmd --permanent --add-port=10250/tcp
$ firewall-cmd --permanent --add-port=10257/tcp
$ firewall-cmd --permanent --add-port=10259/tcp
# 工作节点
$ firewall-cmd --permanent --add-port=10250/tcp
$ firewall-cmd --permanent --add-port=30000-32767/tcp
注意 Pod 网络插件所使用的端口
禁用交换分区
为了保证 kubelet 正常工作,必须禁用交换分区
# 临时禁用
$ swapoff -a
# 永久禁用
$ sed -ri 's/.*swap.*/#&/' /etc/fstab
禁用 SELinux
将 SELinux 设置为 permissive 模式(相当于将其禁用),禁用 SELinux 是允许容器访问主机文件系统所必需的,这些操作是为了例如 Pod 网络工作正常。
$ setenforce 0
$ sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
允许 iptables 检查桥接流量
加载 br_netfilter 模块,br_netfilter 模块用于将桥接流量转发至 iptables 链
$ modprobe br_netfilter
# 确保 br_netfilter 模块已被加载
$ lsmod | grep br_netfilter
为了让 Linux 节点上的 iptables 能够正确地查看桥接流量,需要确保在 sysctl 配置中将 net.bridge.bridge-nf-call-iptables 设置为 1。
$ cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
$ cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
$ sudo sysctl --system
安装 IPVS 所需的内核模块
加载 ipvs 所需的内核模块
# ipvs 模块自动加载配置
$ cat <<EOF | sudo tee /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
# 低版本内核
#modprobe -- nf_conntrack_ipv4
# 高版本内核
modprobe -- nf_conntrack
EOF
# 加载 ipvs 模块并查看是否已经正确加载
#$ chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
# 高版本内核
$ chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
# 安装 ipset
$ yum install ipset -y
# 安装管理工具 ipvsadm,为了后续便于查看 ipvs 的代理规则
$ yum install ipvsadm -y
/etc/sysconfig/modules/ipvs.modules文件确保了节点重启后能自动加载相关模块
如果加载模块报错:
modprobe: FATAL: Module nf_conntrack_ipv4 not found.这是因为在高版本内核中已经把nf_conntrack_ipv4更改为nf_conntrack了。
11、安装容器运行时
本文选择 containerd 作为容器运行时,其他常见的容器运行时安装请参考:容器运行时 | Kubernetes
安装 containerd
Step 1:安装 containerd
本文使用二进制方式安装 containerd,下载官方二进制文件 Releases · containerd/containerd (github.com)
$ wget https://github.com/containerd/containerd/releases/download/v1.6.8/containerd-1.6.8-linux-amd64.tar.gz
在 /usr/local/ 下解压
$ tar Cxzvf /usr/local containerd-1.6.8-linux-amd64.tar.gz
bin/
bin/containerd-shim
bin/containerd
bin/containerd-shim-runc-v1
bin/containerd-stress
bin/containerd-shim-runc-v2
bin/ctr
生成配置文件,containerd 的默认配置文件为 /etc/containerd/config.toml,可以通过如下命令生成一个默认的配置文件
$ mkdir /etc/containerd
$ containerd config default > /etc/containerd/config.toml
systemd 管理 containerd
$ mkdir /usr/local/lib/systemd/system -p
$ curl -fsSL https://raw.githubusercontent.com/containerd/containerd/main/containerd.service -o /usr/local/lib/systemd/system/containerd.service
启动 containerd
$ systemctl daemon-reload
$ systemctl enable --now containerd
查看 containerd 版本信息
$ ctr version
Client:
Version: v1.6.8
Revision: 9cd3357b7fd7218e4aec3eae239db1f68a5a6ec6
Go version: go1.17.13
Server:
Version: v1.6.8
Revision: 9cd3357b7fd7218e4aec3eae239db1f68a5a6ec6
UUID: 0ff1f081-3ee4-4915-915e-47c7f6c14f90
Step 2:安装 runc
下载 runc.<ARCH> 二进制文件 Releases · opencontainers/runc (github.com)
$ wget https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
将其安装为 /usr/local/sbin/runc
$ install -m 755 runc.amd64 /usr/local/sbin/runc
Step 3:安装 CNI 插件
下载 cni-plugins-<OS>-<ARCH>-<VERSION>.tgz 存档 Releases · containernetworking/plugins (github.com)
$ wget https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz
在 /opt/cni/bin 下解压
$ mkdir -p /opt/cni/bin
$ tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.1.1.tgz
./
./macvlan
./static
./vlan
./portmap
./host-local
./vrf
./bridge
./tuning
./firewall
./host-device
./sbr
./loopback
./dhcp
./ptp
./ipvlan
./bandwidth
配置 systemd cgroup 驱动程序
结合 runc 使用 systemd cgroup 驱动,在 /etc/containerd/config.toml 中设置 SystemdCgroup = true
$ sed -i 's,SystemdCgroup = false,SystemdCgroup = true,' /etc/containerd/config.toml
重载沙箱(pause)镜像
设置 sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
$ sed -ri 's,(.*sandbox_image = ).*,\1"registry.aliyuncs.com/google_containers/pause:3.6",' /etc/containerd/config.toml
重启 containerd
$ systemctl restart containerd
安装 CLI 工具(可选)
有几个用于与 containerd 交互的命令行界面 (command line interface - CLI) 项目:
| Name | Community | API | Target | Web site |
|---|---|---|---|---|
ctr |
containerd | Native | For debugging only | (None, see ctr --help to learn the usage) |
nerdctl |
containerd (non-core) | Native | General-purpose | https://github.com/containerd/nerdctl |
crictl |
Kubernetes SIG-node | CRI | For debugging only | https://github.com/kubernetes-sigs/cri-tools/blob/master/docs/crictl.md |
ctr 工具与 containerd 捆绑在一起,但 ctr 工具仅用于调试 containerd。 nerdctl 工具是 Containerd 原生的 CLI 工具,并且兼容 Docker。crictl 为兼容 CRI 的容器运行时提供 CLI。
nerdctl
nerdctl 安装
# Minimal 安装
$ VERSION="0.23.0"
$ wget https://github.com/containerd/nerdctl/releases/download/v$VERSION/nerdctl-$VERSION-linux-amd64.tar.gz
$ tar Cxzvvf /usr/local/bin nerdctl-$VERSION-linux-amd64.tar.gz
$ rm -f nerdctl-$VERSION-linux-amd64.tar.gz
# 查看相关版本信息
$ nerdctl --version
nerdctl version 0.23.0
$ nerdctl version
WARN[0000] unable to determine buildctl version: exec: "buildctl": executable file not found in $PATH
Client:
Version: v0.23.0
OS/Arch: linux/amd64
Git commit: 660680b7ddfde1d38a66ec1c7f08f8d89ab92c68
builctl:
Version:
Server:
containerd:
Version: v1.6.8
GitCommit: 9cd3357b7fd7218e4aec3eae239db1f68a5a6ec6
runc:
Version: 1.1.4
GitCommit: v1.1.4-0-g5fd4c4d1
注意:还需要安装用于使用
nerdctl run的 CNI plugins,本文前面已经安装。还可以安装一些可选的组件,如用于使用nerdctl build的 BuildKit 组件, 用于 Rootless 模式的 RootlessKit 和 slirp4netns 组件。
nerdctl 命令参考
containerd/nerdctl - command-reference (github.com)
crictl
crictl 安装
# 安装
$ VERSION="v1.25.0"
# $ curl -L https://github.com/kubernetes-sigs/cri-tools/releases/download/$VERSION/crictl-${VERSION}-linux-amd64.tar.gz --output crictl-${VERSION}-linux-amd64.tar.gz
$ wget https://github.com/kubernetes-sigs/cri-tools/releases/download/$VERSION/crictl-$VERSION-linux-amd64.tar.gz
$ tar zxvf crictl-$VERSION-linux-amd64.tar.gz -C /usr/local/bin
$ rm -f crictl-$VERSION-linux-amd64.tar.gz
# 配置
$ cat <<EOF | tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 查看相关版本信息
$ crictl --version
crictl version v1.25.0
$ crictl version
Version: 0.1.0
RuntimeName: containerd
RuntimeVersion: v1.6.8
RuntimeApiVersion: v1
crictl 使用
kubernetes-sigs/cri-tools - usage (github.com)
12、安装 kubeadm、kubelet 和 kubectl
添加阿里云 YUM 软件源
$ cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装 kubeadm、kubelet 和 kubectl
$ yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
$ systemctl enable --now kubelet
以上安装命令默认安装最新版本,安装指定版本:
yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
13、为 kube-apiserver 创建负载均衡器
本文使用 kube-vip 为 Kubernetes 集群提供高可用负载均衡服务,kube-vip 将作为静态 pod 在控制平面节点上运行。
kube-vip 为 Kubernetes 集群提供了一个虚拟 IP 和负载均衡器,用于控制平面(用于构建高可用性集群)和 LoadBalancer 类型的 Kubernetes 服务,而不依赖任何外部硬件或软件。
该项目最初旨在为 Kubernetes 提供弹性控制平面,但后来扩展到为 Kubernetes 集群中的服务资源提供相同的功能。
生成清单
为了更轻松地使用 kube-vip 中的各种功能,我们可以使用 kube-vip 容器本身来生成我们的静态 Pod 清单。为此,我们将 kube-vip 映像作为容器运行,并为我们想要启用的功能传入各种标志。
选择一个控制平面节点执行以下操作
设置配置细节
我们使用环境变量来预定义要提供给 kube-vip 的输入值。
$ export VIP=192.168.30.40
$ export INTERFACE=eno1
$ KVVERSION=$(curl -sL https://api.github.com/repos/kube-vip/kube-vip/releases | jq -r ".[0].name")
# 手动设置
#$ export KVVERSION=V0.5.5
yum install epel-release -y && yum install jq -y
创建清单
为容器运行时创建别名,本文使用的是 containerd,所以创建命令如下
$ alias kube-vip="ctr image pull ghcr.io/kube-vip/kube-vip:$KVVERSION; ctr run --rm --net-host ghcr.io/kube-vip/kube-vip:$KVVERSION vip /kube-vip"
docker:
alias kube-vip="docker run --network host --rm ghcr.io/kube-vip/kube-vip:$KVVERSION"
创建一个清单,该清单启动 kube-vip,使用 leaderElection 方法和 ARP 提供控制平面 VIP 和 Kubernetes 服务管理。当这个实例被选举为领导者时,它会将 vip 绑定到指定的接口。这与 LoadBalancer 类型的服务的行为相同。
$ kube-vip manifest pod \
--interface $INTERFACE \
--address $VIP \
--controlplane \
--services \
--arp \
--leaderElection | tee /etc/kubernetes/manifests/kube-vip.yaml
注意:在其余控制平面通过
kubeadm join命令加入到集群之后,需要将主控制平面的kube-vip.yaml文件拷贝到其余控制平台的相应目录。
生成的 ARP 清单示例
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-vip
namespace: kube-system
spec:
containers:
- args:
- manager
env:
- name: vip_arp
value: "true"
- name: port
value: "6443"
- name: vip_interface
value: eno1
- name: vip_cidr
value: "32"
- name: cp_enable
value: "true"
- name: cp_namespace
value: kube-system
- name: vip_ddns
value: "false"
- name: svc_enable
value: "true"
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "5"
- name: vip_renewdeadline
value: "3"
- name: vip_retryperiod
value: "1"
- name: address
value: 192.168.30.40
- name: prometheus_server
value: :2112
image: ghcr.io/kube-vip/kube-vip:v0.5.0
imagePullPolicy: Always
name: kube-vip
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- NET_RAW
volumeMounts:
- mountPath: /etc/kubernetes/admin.conf
name: kubeconfig
hostAliases:
- hostnames:
- kubernetes
ip: 127.0.0.1
hostNetwork: true
volumes:
- hostPath:
path: /etc/kubernetes/admin.conf
name: kubeconfig
status: {}
14、部署高可用 etcd 集群(本文未使用)
默认情况下,kubeadm 在每个控制平面节点上运行一个本地 etcd 实例。也可以使用外部的 etcd 集群,并在不同的主机上提供 etcd 实例。以下创建一个由三个成员组成的高可用外部 etcd 集群,该集群在创建过程中可被 kubeadm 使用。
建立集群
一般来说,是在一个节点上生成所有证书并且只分发这些 必要 的文件到其它节点上。
-
将 kubelet 配置为 etcd 的服务管理器
在要运行 etcd 的所有主机上执行此操作
由于 etcd 是首先创建的,因此你必须通过创建具有更高优先级的新文件来覆盖 kubeadm 提供的 kubelet 单元文件。
$ cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= # 将下面的 "systemd" 替换为你的容器运行时所使用的 cgroup 驱动。 # kubelet 的默认值为 "cgroupfs"。 # 如果需要的话,将 "--container-runtime-endpoint " 的值替换为一个不同的容器运行时。 ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --cgroup-driver=systemd Restart=always EOF $ systemctl daemon-reload $ systemctl restart kubelet检查 kubelet 的状态以确保其处于运行状态:
$ systemctl status kubelet -
为 kubeadm 创建配置文件
使用以下脚本为每个将要运行 etcd 成员的主机生成一个 kubeadm 配置文件
# 使用你的主机 IP 替换 HOST0、HOST1 和 HOST2 的 IP 地址 export HOST0=192.168.20.17 export HOST1=192.168.20.18 export HOST2=192.168.20.19 # 使用你的主机名更新 NAME0、NAME1 和 NAME2 export NAME0="m1" export NAME1="m2" export NAME2="m3" # 创建临时目录来存储将被分发到其它主机上的文件 mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/ HOSTS=(${HOST0} ${HOST1} ${HOST2}) NAMES=(${NAME0} ${NAME1} ${NAME2}) for i in "${!HOSTS[@]}"; do HOST=${HOSTS[$i]} NAME=${NAMES[$i]} cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml --- apiVersion: "kubeadm.k8s.io/v1beta3" kind: InitConfiguration nodeRegistration: name: ${NAME} localAPIEndpoint: advertiseAddress: ${HOST} --- apiVersion: "kubeadm.k8s.io/v1beta3" kind: ClusterConfiguration etcd: local: serverCertSANs: - "${HOST}" peerCertSANs: - "${HOST}" extraArgs: initial-cluster: ${NAMES[0]}=https://${HOSTS[0]}:2380,${NAMES[1]}=https://${HOSTS[1]}:2380,${NAMES[2]}=https://${HOSTS[2]}:2380 initial-cluster-state: new name: ${NAME} listen-peer-urls: https://${HOST}:2380 listen-client-urls: https://${HOST}:2379 advertise-client-urls: https://${HOST}:2379 initial-advertise-peer-urls: https://${HOST}:2380 EOF done -
生成证书颁发机构
如果已经拥有 CA,那么直接复制 CA 的
crt和key文件到/etc/kubernetes/pki/etcd/ca.crt和/etc/kubernetes/pki/etcd/ca.key。 复制完这些文件后继续“为每个成员创建证书”。如果还没有 CA,则在
$HOST0(为 kubeadm 生成配置文件的位置)上运行此命令。$ kubeadm init phase certs etcd-ca [certs] Generating "etcd/ca" certificate and key这一操作创建如下两个文件:
/etc/kubernetes/pki/etcd/ca.crt/etc/kubernetes/pki/etcd/ca.key
-
为每个成员创建证书
kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml cp -R /etc/kubernetes/pki /tmp/${HOST2}/ # 清理不可重复使用的证书 find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml cp -R /etc/kubernetes/pki /tmp/${HOST1}/ find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml # 不需要移动 certs 因为它们是给 HOST0 使用的 # 清理不应从此主机复制的证书 find /tmp/${HOST2} -name ca.key -type f -delete find /tmp/${HOST1} -name ca.key -type f -delete -
复制证书和 kubeadm 配置
证书已生成,现在将它们移动到对应的主机。
USER=root HOST=${HOST1} scp -r /tmp/${HOST}/* ${USER}@${HOST}:/etc/kubernetes/ ssh ${USER}@${HOST} USER@HOST $ sudo -Es root@HOST $ chown -R root:root pki root@HOST $ mv pki /etc/kubernetes/ -
确保所有拷贝的文件都存在
$HOST0所需文件的完整列表如下:/tmp/${HOST0} └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── ca.key ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key在
$HOST1上:$HOME └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key在
$HOST2上:$HOME └── kubeadmcfg.yaml --- /etc/kubernetes/pki ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key └── etcd ├── ca.crt ├── healthcheck-client.crt ├── healthcheck-client.key ├── peer.crt ├── peer.key ├── server.crt └── server.key -
创建静态 Pod 清单
在每台主机上运行
kubeadm命令来生成 etcd 使用的静态清单root@HOST0 $ kubeadm init phase etcd local --config=/tmp/${HOST0}/kubeadmcfg.yaml root@HOST1 $ kubeadm init phase etcd local --config=$HOME/kubeadmcfg.yaml root@HOST2 $ kubeadm init phase etcd local --config=$HOME/kubeadmcfg.yaml -
可选:检查集群运行状况
$ docker run --rm -it \ --net host \ -v /etc/kubernetes:/etc/kubernetes k8s.gcr.io/etcd:${ETCD_TAG} etcdctl \ --cert /etc/kubernetes/pki/etcd/peer.crt \ --key /etc/kubernetes/pki/etcd/peer.key \ --cacert /etc/kubernetes/pki/etcd/ca.crt \ --endpoints https://${HOST0}:2379 endpoint health --cluster ... https://[HOST0 IP]:2379 is healthy: successfully committed proposal: took = 16.283339ms https://[HOST1 IP]:2379 is healthy: successfully committed proposal: took = 19.44402ms https://[HOST2 IP]:2379 is healthy: successfully committed proposal: took = 35.926451ms- 将
${ETCD_TAG}设置为你的 etcd 镜像的版本标签,例如3.4.3-0。 要查看 kubeadm 使用的 etcd 镜像和标签,请执行kubeadm config images list --kubernetes-version ${K8S_VERSION}, 例如,其中的${K8S_VERSION}可以是v1.17.0。 - 将
${HOST0}设置为要测试的主机的 IP 地址。
- 将
15、初始化 K8S 集群
初始化主控制平面
本文通过一份配置文件而不是使用命令行参数来配置 kubeadm init 命令, 一些更加高级的功能只能够通过配置文件设定。 这份配置文件通过 --config 选项参数指定的, 它必须包含 ClusterConfiguration 结构,并可能包含更多由 ---\n 分隔的结构。 在某些情况下,可能不允许将 --config 与其他标志混合使用。详情请查看:kubeadm config | Kubernetes
Step 1:准备 kubeadm init 命令的配置文件:kubeadm-config.yaml
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
# nodeRegistration:
# name: m1
# criSocket: unix:///var/run/cri-dockerd.sock
localAPIEndpoint:
advertiseAddress: 192.168.30.37
bindPort: 6443
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
#kubernetesVersion: 1.25.2
kubernetesVersion: stable
# 可以指定 TCP 端口号,会覆盖 bindPort
# 如果不指定端口号,则使用 bindPort
# controlPlaneEndpoint: 192.168.20.236:8443
controlPlaneEndpoint: 192.168.30.40
apiServer:
certSANs:
- k8s-master01
- k8s-master02
- k8s-master03
- 192.168.30.37
- 192.168.30.38
- 192.168.30.39
- vip.mycluster.local
- 192.168.30.40
- 127.0.0.1
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
clusterName: kubernetes
certificatesDir: /etc/kubernetes/pki
imageRepository: registry.aliyuncs.com/google_containers
etcd:
# one of local or external
local:
dataDir: /var/lib/etcd
# external:
# endpoints:
# - 192.168.20.17:2379
# - 192.168.20.18:2379
# - 192.168.20.19:2379
# caFile: /etcd/kubernetes/pki/etcd/etcd-ca.crt
# certFile: /etcd/kubernetes/pki/etcd/etcd.crt
# keyFile: /etcd/kubernetes/pki/etcd/etcd.key
networking:
serviceSubnet: 10.96.0.0/16
podSubnet: 10.244.0.0/24
dnsDomain: cluster.local
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
Step 2:初始化主控制平面
$ kubeadm init --config kubeadm-config.yaml --upload-certs
...
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.30.40:6443 --token t8wmx7.stp4utmdm5m43ob7 \
--discovery-token-ca-cert-hash sha256:d8ac2f0a9652308e67c0d3a36de2321261752d47679ad33e7c4026f61359ab7d \
--control-plane --certificate-key c7d3e3622c1a234e6f82cf550ea4e2a581991aec36341b0edcb84ea87f127b38
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.30.40:6443 --token t8wmx7.stp4utmdm5m43ob7 \
--discovery-token-ca-cert-hash sha256:d8ac2f0a9652308e67c0d3a36de2321261752d47679ad33e7c4026f61359ab7d
--upload-certs标志用来将在所有控制平面实例之间的共享证书上传到集群。主控制平面的证书被加密并上传到kubeadm-certsSecret 中。重新上传证书并生成新的解密密钥:
kubeadm init phase upload-certs --upload-certs
其余控制平面加入集群
在其余的控制平面执行以下命令加入集群
$ kubeadm join 192.168.30.40:6443 --token t8wmx7.stp4utmdm5m43ob7 \
--discovery-token-ca-cert-hash sha256:d8ac2f0a9652308e67c0d3a36de2321261752d47679ad33e7c4026f61359ab7d \
--control-plane --certificate-key c7d3e3622c1a234e6f82cf550ea4e2a581991aec36341b0edcb84ea87f127b38
kubelet 日志:
journalctl -u kubelet -f相关报错:
"Failed to create cgroup" err="Cannot set property TasksAccounting, or unknown property." cgroupName=[kubepods],需要更新 systemd:yum update systemd -y
在主控制平面复制 kube-vip 清单文件到其余的控制平面节点,注意将 vip_interface 项的值修改为各自节点的网卡名称。
$ for i in m2 m3;do scp /etc/kubernetes/manifests/kube-vip.yaml root@$i:/etc/kubernetes/manifests/;done
安装工作节点
在所有工作节点上执行以下命令加入集群
$ kubeadm join 192.168.30.40:6443 --token t8wmx7.stp4utmdm5m43ob7 \
--discovery-token-ca-cert-hash sha256:d8ac2f0a9652308e67c0d3a36de2321261752d47679ad33e7c4026f61359ab7d
附:创建引导令牌
kubeadm init 创建了一个有效期为 24 小时的令牌,当令牌过期后无法再使用此令牌添加工作节点到现有集群,可以使用如下命令生成新的令牌并打印使用此令牌加入集群所需的完整 ‘kubeadm join’ 参数。
# 在主控制平面节点执行以下命令生成新的令牌
$ kubeadm token create --config ./kubeadm-config.yaml --print-join-command
kubeadm join 192.168.30.40:6443 --token nrm8nn.3dnwi8yfncqxdzeh --discovery-token-ca-cert-hash sha256:d8ac2f0a9652308e67c0d3a36de2321261752d47679ad33e7c4026f61359ab7d
查看引导令牌
$ kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
nrm8nn.3dnwi8yfncqxdzeh 23h 2022-10-14T08:27:44Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
16、配置 kubectl 命令
配置使用 kubectl 命令
-
非 root 用户
$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config -
root 用户
$ echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile $ source /etc/profile
启动 kubectl 自动补全
kubectl 的 Bash 补全脚本可以用命令 kubectl completion bash 生成。 在 shell 中导入(Sourcing)补全脚本,将启用 kubectl 自动补全功能。补全脚本依赖于工具 bash-completion, 所以要先安装它。
# 检查 bash-completion 是否已安装
$ type _init_completion
# 安装 bash-completion
$ yum install bash-completion -y
# 加载 completion
$ source /usr/share/bash-completion/bash_completion
# 启动 kubectl 自动补全
# 当前用户
# $ echo 'source <(kubectl completion bash)' >>~/.bashrc
# 系统全局
$ kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
# 如果 kubectl 有关联的别名,可以扩展 shell 补全来适配此别名
$ echo 'alias k=kubectl' >>~/.bashrc && source ~/.bashrc
$ echo 'complete -o default -F __start_kubectl k' >>~/.bashrc
说明:
bash-completion 负责导入
/etc/bash_completion.d目录中的所有补全脚本。重新加载 shell 后,kubectl 自动补全功能才生效。
17、安装 Pod network
本文使用 Cilium 。Cilium 是开源软件,用于透明地保护使用 Linux 容器管理平台(如 Docker 和 Kubernetes)部署的应用程序服务之间的网络连接和负载平衡。Cilium 在第 3/4 层运行以提供传统的网络和安全服务,并在第 7 层运行以保护和保护现代应用程序协议(如 HTTP、gRPC 和 Kafka)的使用。 Cilium 被集成到 Kubernetes 等常见的编排框架中。
安装 cilium
安装 Cilium CLI
安装最新版本的 Cilium CLI。 Cilium CLI 可用于安装 Cilium、检查 Cilium 安装的状态以及启用/禁用各种功能(例如 clustermesh、Hubble)
$ wget https://github.com/cilium/cilium-cli/releases/download/v0.12.4/cilium-linux-amd64.tar.gz
$ tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
$ rm -f cilium-linux-amd64.tar.gz
安装 Cilium
要求:
- Kubernetes 必须配置为使用 CNI
- Linux kernel >= 4.9.17
安装 Cilium
将 Cilium 安装到当前 kubectl 上下文指向的 Kubernetes 集群中:
$ cilium install
ℹ️ Using Cilium version 1.12.2
🔮 Auto-detected cluster name: kubernetes
🔮 Auto-detected datapath mode: tunnel
🔮 Auto-detected kube-proxy has been installed
ℹ️ helm template --namespace kube-system cilium cilium/cilium --version 1.12.2 --set cluster.id=0,cluster.name=kubernetes,encryption.nodeEncryption=false,kubeProxyReplacement=disabled,operator.replicas=1,serviceAccounts.cilium.name=cilium,serviceAccounts.operator.name=cilium-operator,tunnel=vxlan
ℹ️ Storing helm values file in kube-system/cilium-cli-helm-values Secret
🔑 Created CA in secret cilium-ca
🔑 Generating certificates for Hubble...
🚀 Creating Service accounts...
🚀 Creating Cluster roles...
🚀 Creating ConfigMap for Cilium version 1.12.2...
🚀 Creating Agent DaemonSet...
🚀 Creating Operator Deployment...
⌛ Waiting for Cilium to be installed and ready...
✅ Cilium was successfully installed! Run 'cilium status' to view installation health
如果由于某种原因安装失败,请运行 cilium status 以检索 Cilium 部署的整体状态,并检查任何未能部署的 pod 的日志。
验证安装
要验证 Cilium 是否已正确安装,您可以运行
$ cilium status --wait
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Hubble: disabled
\__/¯¯\__/ ClusterMesh: disabled
\__/
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
DaemonSet cilium Desired: 5, Ready: 5/5, Available: 5/5
Containers: cilium Running: 5
cilium-operator Running: 1
Cluster Pods: 2/2 managed by Cilium
Image versions cilium-operator quay.io/cilium/operator-generic:v1.12.2@sha256:00508f78dae5412161fa40ee30069c2802aef20f7bdd20e91423103ba8c0df6e: 1
cilium quay.io/cilium/cilium:v1.12.2@sha256:986f8b04cfdb35cf714701e58e35da0ee63da2b8a048ab596ccb49de58d5ba36: 5
查看 Cilium 相关版本
$ cilium version
cilium-cli: v0.12.4 compiled with go1.19.1 on linux/amd64
cilium image (default): v1.12.2
cilium image (stable): v1.12.2
cilium image (running): v1.12.2
验证集群是否具有正确的网络连接:
cilium connectivity test
18、查看集群状态
$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.30.40:6443
CoreDNS is running at https://192.168.30.40:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 13h v1.25.2
k8s-master02 Ready control-plane 13h v1.25.2
k8s-master03 Ready control-plane 13h v1.25.2
k8s-node01 Ready <none> 12h v1.25.2
k8s-node02 Ready <none> 12h v1.25.2
$ kubectl get componentstatus
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
至此,K8S 集群已部署完毕。
20、其他配置
为节点添加角色标签
以下命令为 master, worker 标签示例,应该给其他所有节点都添加上其对应角色的标签
$ kubectl label node k8s-master01 node-role.kubernetes.io/master=master
$ kubectl label node k8s-node01 node-role.kubernetes.io/worker=worker
查看节点信息
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane,master 13h v1.25.2
k8s-master02 Ready control-plane,master 13h v1.25.2
k8s-master03 Ready control-plane,master 13h v1.25.2
k8s-node01 Ready worker 13h v1.25.2
k8s-node02 Ready worker 13h v1.25.2
30、安装 NFS Subdir External Provisioner
NFS subdir external provisioner 是一个自动供应器,它使用你现有的和已经配置好的 NFS 服务器,通过持久卷声明支持 Kubernetes 持久卷的动态供应。持久卷以 ${namespace}-${pvcName}-${pvName} 的形式进行配置。
需要注意的是,必须已经有一个 NFS 服务器。
Linux 搭建 NFS 服务 - KILL TIME OR KISS TIME (aluopy.cn)
Step 1: 获取 NFS 服务器的连接信息
确保 NFS 服务器可以从 Kubernetes 集群中访问,并获得需要的信息以连接到它。至少需要它的主机名。
NFS_SERVER: 192.168.20.56
NFS_PATH: /home/sdzfp/a9kpfw
Step 2: 获取 NFS Subdir External Provisioner 文件
为了设置 provisioner,你将下载一组YAML文件,编辑它们以添加你的 NFS 服务器的连接信息,然后用 kubectl / oc 命令分别应用。
获取 kubernetes-sigs/nfs-subdir-external-provisioner 储存库的 deploy 目录中的所有文件。
Step 3: 设置授权
如果你的集群启用了 RBAC,或者你正在运行 OpenShift,你必须授权供应者。如果你在 “default” 以外的命名空间/项目中,编辑 deploy/rbac.yaml。
# 本文部署到 kube-system 命名空间
$ NAMESPACE=kube-system
$ sed -i'' "s,namespace:.*,namespace: $NAMESPACE,g" rbac.yaml deployment.yaml
$ kubectl apply -f rbac.yaml
Step 4: 配置部署 NFS subdir external provisioner
修改为自定义构建的 nfs-subdir-external-provisioner 镜像、设置 NFS 服务器信息:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
#image: k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
image: registry.cn-shenzhen.aliyuncs.com/aluopy/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: aisino/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.20.56
- name: NFS_PATH
value: /home/sdzfp/a9kpfw
volumes:
- name: nfs-client-root
nfs:
server: 192.168.20.56
path: /home/sdzfp/a9kpfw
Deploy:
$ kubectl apply -f deployment.yaml
nfs-client-provisioner pod 启动报错:
Output: mount: wrong fs type, bad option, bad superblock on 192.168.20.56:/home/sdzfp/a9kpfw, missing codepage or helper program, or other error.需要安装 NFS 客户端:
yum install nfs-utils -y
Step 5: 部署 storage class
这是 class.yaml,它定义了 NFS subdir external provisioner 的 Kubernetes 存储类。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
annotations:
storageclass.kubernetes.io/is-default-class: "true" # Set to default class
provisioner: aisino/nfs-subdir-external-provisioner # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
pathPattern: "${.PVC.namespace}/${.PVC.annotations.nfs.io/storage-path}" # for deployment, waits for nfs.io/storage-path annotation, if not specified will accept as empty string.
#pathPattern: ${.PVC.namespace}-${.PVC.name} # for sts
onDelete: delete
parameters.pathPattern指定一个模板,用于通过 PVC 元数据(如标签、注释、名称或命名空间)创建目录路径。要指定元数据,使用${.PVC.<metadata>}。例子:如果文件夹要命名为<pvc-namespace>-<pvc-name>,请使用${.PVC.namespace}-${.PVC.name}作为 pathPattern。本文设置的目录路径是通过设置 PVC 注解
annotations.nfs.io/storage-path传入的。
Deploy:
$ kubectl apply -f class.yaml
Step 6: 最后,测试你的环境!
$ kubectl apply -f test-claim.yaml -f test-pod.yaml
Step 7: 部署自己的 PersistentVolumeClaims
示例:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
annotations:
nfs.io/storage-path: "test-path" # 设置挂载到 NFS 服务器的目录路径
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
31、安装 kube-vip Cloud Provider
kube-vip cloud provider 可以用来为 LoadBalancer 类型的服务填充一个 IP 地址,类似于公共云提供商通过Kubernetes CCM 允许的那样。
Install the kube-vip Cloud Provider
kube-vip cloud provider 可以通过使用以下命令从 main 分支的最新版本中安装。
$ kubectl apply -f https://raw.githubusercontent.com/kube-vip/kube-vip-cloud-provider/main/manifest/kube-vip-cloud-controller.yaml
查看 kube-vip cloud provider 运行状态
$ kubectl get pod -n kube-system -l component=kube-vip-cloud-provider
NAME READY STATUS RESTARTS AGE
kube-vip-cloud-provider-9d4f47dc6-fc5lq 1/1 Running 1 (27h ago) 28h
Using the kube-vip Cloud Provider
要使用 LoadBalancer service,还需要安装 kube-vip 组件(本文前面已安装)。
$ kubectl get pod -n kube-system | grep kube-vip
kube-vip-cloud-provider-9d4f47dc6-fc5lq 1/1 Running 1 (28h ago) 28h
kube-vip-k8s-master01 1/1 Running 1 (28h ago) 28h
kube-vip-k8s-master02 1/1 Running 0 27h
kube-vip-k8s-master03 1/1 Running 0 27h
kube-vip cloud provider 负责填充 spec.loadBalancerIP,当为 kube-vip 启用 service(svc_enable: true)时,会在所有符合 LoadBalancer 类型的服务上启用一个 watcher。只有在 spec.loadBalancerIP 被填入后,”watcher” 才会公布一个 kubernetes service。此外,kube-vip 可以根据各种注释忽略对 service 采取行动。
loadBalancerIP 可以在 service 中直接指定,也可以创建一个全局或仅限于特定命名空间的 IP 范围来给 kube-vip 使用。
方式一:在 service 中定义 loadBalancerIP:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- name: http
port: 80
protocol: TCP
selector:
app: nginx
type: LoadBalancer
loadBalancerIP: "192.168.30.31"
方式二:要使用一个全局范围,请创建密钥 range-global,其值设置为有效的 IP 地址范围。例如,下面的命令使用池192.168.1.220-192.168.1.230 创建一个全局范围。
$ kubectl create configmap -n kube-system kubevip --from-literal range-global=192.168.30.71-192.168.30.79
使用 yaml 文件创建 ConfigMap:
apiVersion: v1
data:
range-global: 192.168.30.71-192.168.30.79
kind: ConfigMap
metadata:
name: kubevip
namespace: kube-system
32、安装 Kubernetes Dashboard
简介
Kubernetes Dashboard 是一个通用的、基于 Web 的 Kubernetes 集群用户界面。它允许用户管理集群中运行的应用程序,并对其进行故障排除,以及管理集群本身。
部署
运行以下命令部署 Dashboard
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
本文
kubernetes-dashboard服务使用的是LoadBalancer模式,已提前修改好相关配置。
查看相关资源
$ kubectl get pod,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-64bcc67c9c-t4s6h 1/1 Running 0 16h
pod/kubernetes-dashboard-5c8bd6b59-dnn5m 1/1 Running 0 16h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.96.117.128 <none> 8000/TCP 16h
service/kubernetes-dashboard LoadBalancer 10.96.196.103 192.168.30.28 443:31064/TCP 16h
创建认证令牌(RBAC)
在本步骤,我们将了解如何使用 Kubernetes 的服务账户机制创建一个新用户,授予该用户管理权限,并使用与该用户绑定的承载令牌登录 Dashboard。
创建一个服务账户
我们首先在命名空间 kubernetes-dashboard 中创建名为 admin-user 的服务账户。
dashboard-adminuser.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
应用 YAML 文件
$ kubectl apply -f dashboard-adminuser.yaml
创建一个 ClusterRoleBinding
在大多数情况下,在使用 kops、kubeadm 或任何其他流行的工具配置集群后,集群中已经存在 ClusterRole cluster-admin。我们可以使用它,只为我们的 ServiceAccount 创建一个 ClusterRoleBinding。如果它不存在,那么需要先创建这个角色并手动授予所需的权限。
dashboard-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
应用 YAML 文件
$ kubectl apply -f dashboard-rbac.yaml
获得承载令牌
执行以下命令创建登录令牌
$ kubectl -n kubernetes-dashboard create token admin-user
它应该打印出类似的内容:
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXY1N253Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwMzAzMjQzYy00MDQwLTRhNTgtOGE0Ny04NDllZTliYTc5YzEiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.Z2JrQlitASVwWbc-s6deLRFVk5DWD3P_vjUFXsqVSY10pbjFLG4njoZwh8p3tLxnX_VBsr7_6bwxhWSYChp9hwxznemD5x5HLtjb16kI9Z7yFWLtohzkTwuFbqmQaMoget_nYcQBUC5fDmBHRfFvNKePh_vSSb2h_aYXa8GV5AcfPQpY7r461itme1EXHQJqv-SN-zUnguDguCTjD80pFZ_CmnSE1z9QdMHPB8hoB4V68gtswR1VLa6mSYdgPwCHauuOobojALSaMc3RH7MmFUumAgguhqAkX3Omqd3rJbYOMRuMjhANqd08piDC3aIabINX6gP5-Tuuw2svnV6NYQ
访问
访问 Dashboard:
https://192.168.30.28
复制令牌并将其粘贴到登录屏幕上的输入令牌区域。
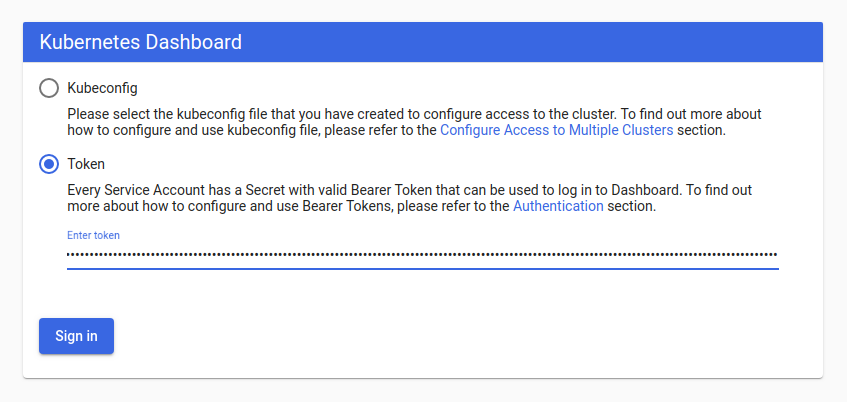
点击 “登录 “按钮,就可以了。你现在是以管理员身份登录的。
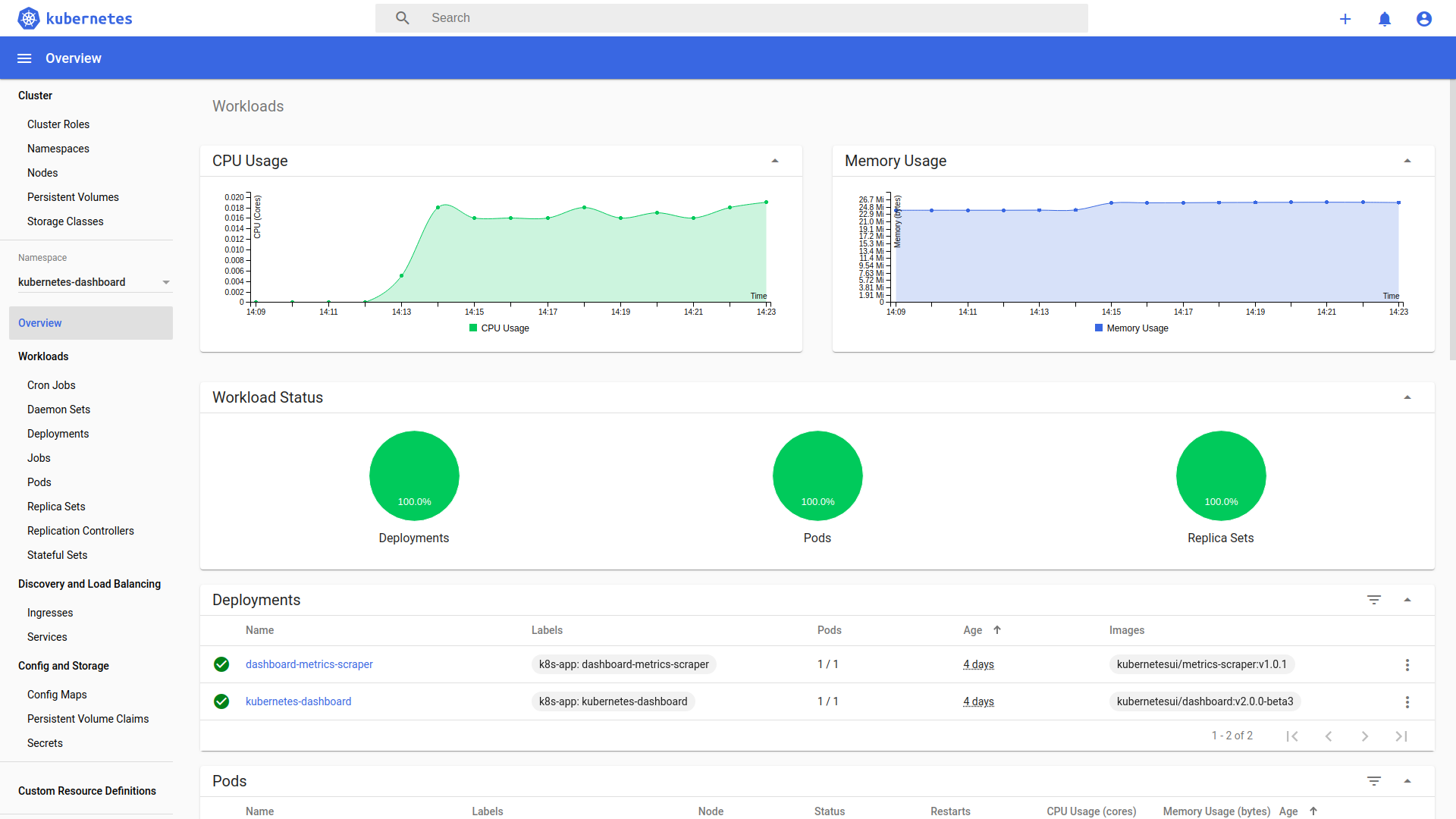
清理和下一步措施
删除 admin 的 ServiceAccount 和 ClusterRoleBinding
kubectl -n kubernetes-dashboard delete serviceaccount admin-user
kubectl -n kubernetes-dashboard delete clusterrolebinding admin-user
